TechTalks are high-level thoughts from our engineering team about what they’re working on
Background - It’s Time to Move
As a service grows, there comes a time where pieces need to change. At a high level our system is as follows:
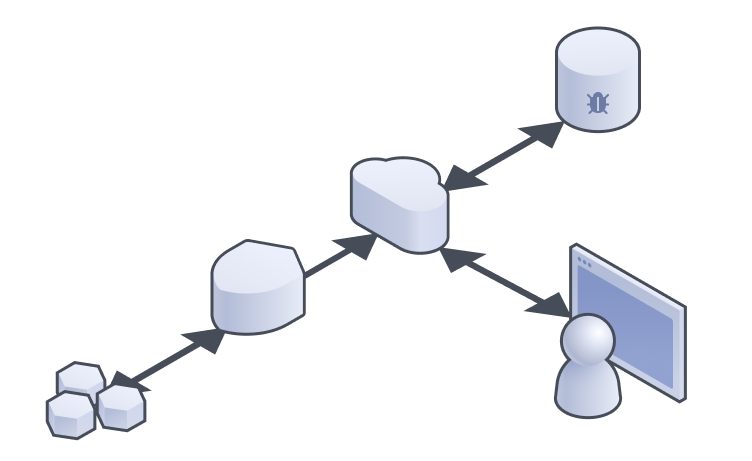
- A large number of devices (BinBars) are connected through…
- a secure IOT portal to…
- An ingestion endpoint comprised of serverless functions that then…
- Forwards the data to a graph database.
- Customers access this database, proxied through a well defined set of APIs, also comprised of serverless functions
This based on Jamstack Architecture, which allows apps that scale implicitly and are easier to secure.
So what’s our problem? We have a simple architecture that scales well, except for one thing: the database.
The graph database (lovingly marked with the bug icon) is too rigid for the rapid iteration we’re doing. Additionally, although all other parts of our architecture are serverless, the graph database is a shared instance that occasionally slows down to the point that we get timeouts.
Additionally, as we have grown, it’s become clear that while we can model our data as a graph, that’s not necessarily the most sensible option (blurred because secret 😉)…
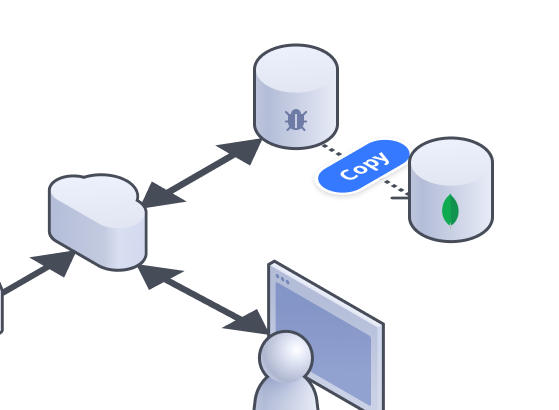
So, time to move to MongoDB! Serverless products, easier data modeling, great tooling (and as a bonus, it’s way more cost effective).
How? - Changing the Engine while the Plane is Flying
We don’t do downtime. Modern architectures and rapid deployments mean it’s no longer necessary. Instead, you (1) copy existing data, (2) fork writes, (3) swap over reads, (4) compare and pray (5) un-fork writes and celebrate.
Copy existing data. This is simple enough, except that we need to modify our data model slightly to fit into MongoDB’s Data Document Model.
After the data is transformed and copied (ideally, immediately after), you fork ingestion of data into the new database. Because all interaction with our database is proxied by serverless functions, it’s as simple as modifying all of these functions to write into both databases. Note that reads still come from the initial database. Nothing about the rest of the system is changed.
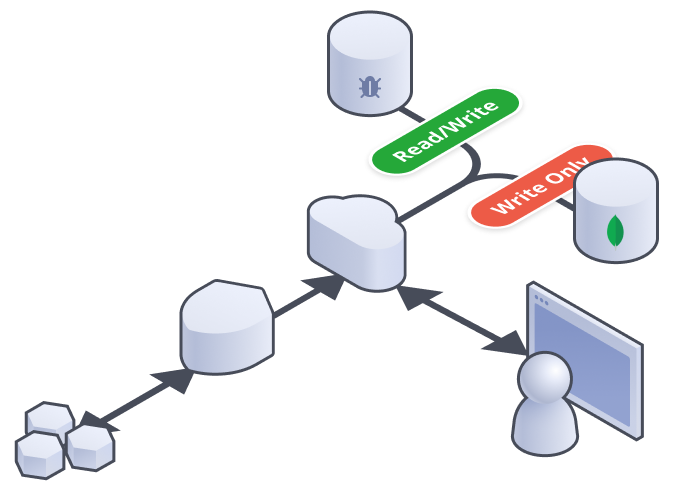
Monitor this for a bit. Assuming it’s going well, it’s time to start pulling reads from the new database. We don’t turn of writes to the old database just yet, just in case 😳
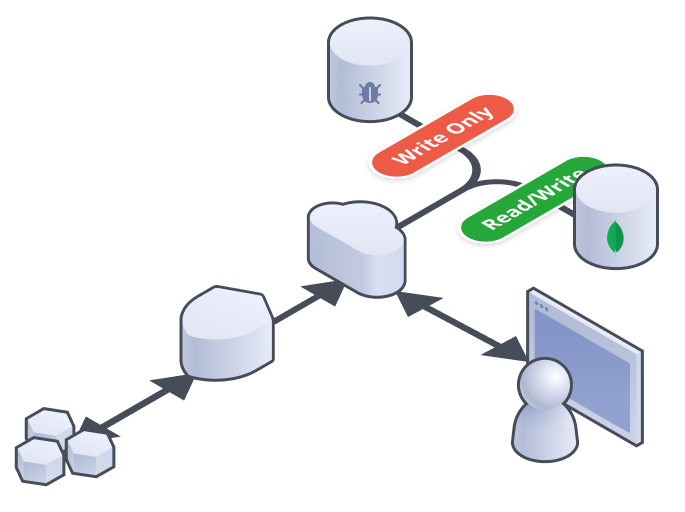
At this point, all users are using the new database without even realizing it! Before turning off the old database, we actually continue to read from both and compare the results. We simply throw the result of the old database away, but this builds confidence. Enough confidence to delete the old database!
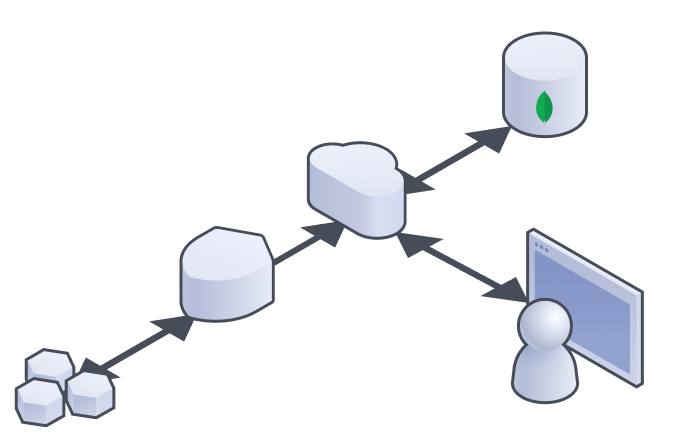
So what?
Truthfully, this isn’t that complex, and that’s the point. By keeping a simple architecture, the pieces of the system can be carefully swapped out and upgraded without anyone noticing.
Thank you to MongoDB for supporting us. If you’re thinking about upgrading your data story, consider exploring #MongoDBStartups